哈希表基础知识 哈希表是根据关键码的值而直接进行访问的数据结构。
数组其实就是一张哈希表
哈希表中关键码就是数组的索引下标,然后通过下标直接访问数组中的元素,如下图所示:
那么哈希表能解决什么问题呢,一般哈希表都是用来快速判断一个元素是否出现集合里。
例如要查询一个名字是否在这所学校里。
要枚举的话时间复杂度是O(n),但如果使用哈希表的话, 只需要O(1)就可以做到。
我们只需要初始化把这所学校里学生的名字都存在哈希表里,在查询的时候通过索引直接就可以知道这位同学在不在这所学校里了。
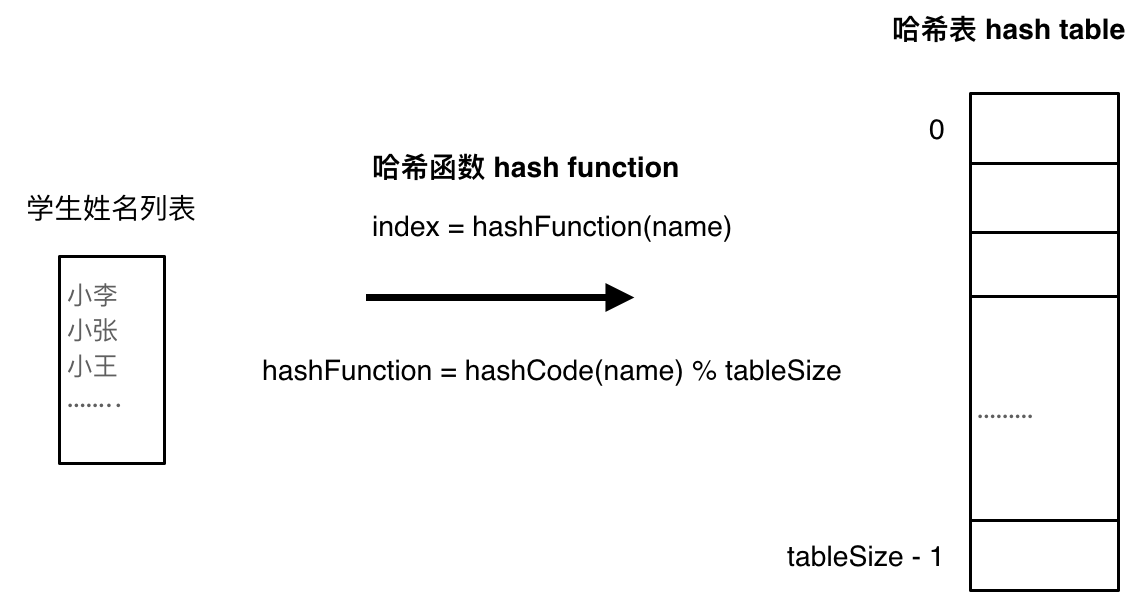
将学生姓名映射到哈希表上就涉及到了hash function ,也就是哈希函数 。
哈希函数 哈希函数,把学生的姓名直接映射为哈希表上的索引,然后就可以通过查询索引下标快速知道这位同学是否在这所学校里了。
哈希函数如下图所示,通过hashCode把名字转化为数值,一般hashcode是通过特定编码方式,可以将其他数据格式转化为不同的数值,这样就把学生名字映射为哈希表上的索引数字了。
如果hashCode得到的数值大于 哈希表的大小了,也就是大于tableSize了,怎么办呢?
此时为了保证映射出来的索引数值都落在哈希表上,我们会在再次对数值做一个取模的操作,就要我们就保证了学生姓名一定可以映射到哈希表上了。
此时问题又来了,哈希表我们刚刚说过,就是一个数组。
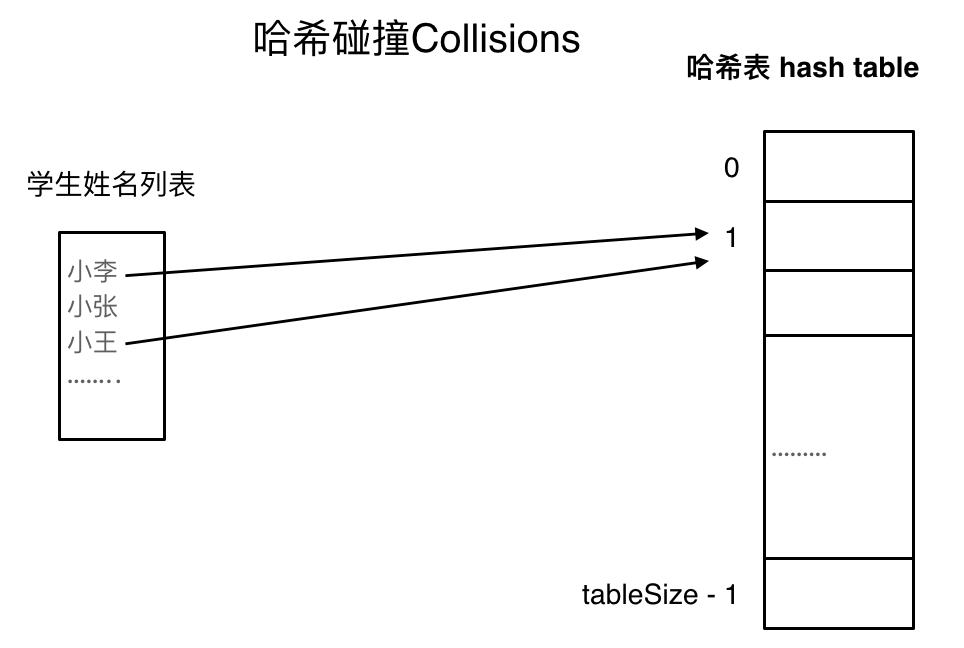
如果学生的数量大于哈希表的大小怎么办,此时就算哈希函数计算的再均匀,也避免不了会有几位学生的名字同时映射到哈希表 同一个索引下标的位置。
接下来哈希冲突 登场
哈希冲突 如图所示,小李和小王都映射到了索引下标 1 的位置,这一现象叫做哈希碰撞 。
如何解决这种冲突呢? 常见的情况有两种方案
链地址法 图示:
从图片中我们可以看出, 链地址法解决冲突的办法是每个数组单元中存储的不再是单个数据, 而是一个链条。
这个链条常见的数据结构是数组或者链表。
比如是链表, 也就是每个数组单元中存储着一个链表。一旦发现重复, 将重复的元素插入到链表的首端或者末端即可
当查询时, 先根据哈希化后的下标值找到对应的位置, 再取出链表, 依次查询找寻找的数据。
线性探测法 图示:
从图片的文字中我们可以了解到, 开放地址法其实就是要寻找空白的位置来放置冲突的数据项。
但是探索这个位置的方式不同, 有三种方法:
线性探测 线性探测非常好理解: 线性的查找空白的单元。
举例:
插入32
经过哈希化得到的index=2, 但是在插入的时候, 发现该位置已经有了82。
线性探测就是从index位置+1开始一点点查找合适的位置来放置32
空的位置就是合适的位置, 在我们上面的例子中就是index=3的位置, 这个时候32就会放在该位置。
查询32
首先经过哈希化得到index=2, 比如2的位置结果和查询的数值是否相同, 相同那么就直接返回。
不相同就线性查找, 从index位置+1开始查找和32一样的。
这里有一个特别需要注意的地方: 如果32的位置我们之前没有插入, 是否将整个哈希表查询一遍来确定32存不存在吗?
当然不是, 查询过程有一个约定, 就是查询到空位置, 就停止。(因为查询到这里有空位置, 32之前不可能跳过空位置去其他的位置)
线性探测的问题:
线性探测有一个比较严重的问题, 就是聚集。比如我在没有任何数据的时候, 插入的是22-23-24-25-26, 那么意味着下标值:2-3-4-5-6的位置都有元素。这种一连串填充单元就叫做聚集。聚集会影响哈希表的性能, 无论是插入/查询/删除都会影响。
二次探测 我们刚才谈到, 线性探测存在的问题: 就是如果之前的数据时连续插入的, 那么新插入的一个数据可能需要探测很长的距离。
二次探测在线性探测的基础上进行了优化:
线性探测, 我们可以看成是步长为1的探测, 比如从下标值x开始, 那么线性测试就是x+1, x+2, x+3依次探测
二次探测, 对步长做了优化, 比如从下标值x开始, x+1², x+2², x+3²
这样就可以一次性探测比较常的距离, 比避免那些聚集带来的影响
二次探测的问题:
设计哈希函数 目前计算机专家已经设计出了非常好的哈希函数,我们只要学会使用就行了。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 HashTable .prototype hashFunc = function (str, size ) { var hashCode = 0 ; for (var i = 0 ; i < str.length ; i++) { hashCode = hashCode * 37 + str.charCodeAt (i); } var index = hashCode % size; return index; }
实现自己的哈希表 创建哈希表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 function HashTable ( this .storage = []; this .count = 0 ; this .limit = 7 ; HashTable .prototype hashFunc = function (str, size ) { var hashCode = 0 ; for (var i = 0 ; i < str.length ; i++) { hashCode = hashCode * 37 + str.charCodeAt (i); } var index = hashCode % size; return index; } }
插入&修改数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 HashTable .prototype put = function (key, value ) { var index = this .hashFunc (key, this .limit ); var bucket = this .storage [index] if (bucket === undefined ) { bucket = []; this .storage [index] = bucket; } for (var i = 0 ; i < bucket.length ; i++) { var tuple = bucket[i]; if (key == tuple[0 ]) { tuple[1 ] = value; return } } bucket.push ([key, value]); this .count += 1 ; }
获取数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 HashTable .prototype get = function (key ) { var index = this .hashFunc (key, this .limit ); var bucket = this .storage [index]; if (bucket == null ) { return null ; } for (var i = 0 ; i < bucket.length ; i++) { var tuple = bucket[i]; if (key = tuple[0 ]) { return tuple[1 ]; } } return null ; }
删除数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 HashTable .prototype remove = function (key ) { var index = this .hashFunc (key, this .limit ); var bucket = this .storage [index]; if (bucket == null ) return null ; for (var i = 0 ; i < bucket.length ; i++) { var tuple = bucket[i]; if (key == tuple[0 ]) { bucket.splice (i, 1 ); this .count -= 1 ; return tuple[1 ]; } } return null ; }
其他方法 1 2 3 4 5 6 7 8 9 HashTable .prototype isEmpty = function ( return this .count == 0 } HashTable .prototype size = function ( return this .count }
哈希表扩容 为什么需要扩容?
目前, 我们是将所有的数据项放在长度为8的数组中的
因为我们使用的是链地址法, loadFactor可以大于1, 所以这个哈希表可以无限制的插入新数据
但是, 随着数据量的增多, 每一个index对应的bucket会越来越长, 也就造成效率的降低
所以, 在合适的情况对数组进行扩容. 比如扩容两倍
如何进行扩容?
扩容后的数量最好是质数(质数是计算机专家得出哈希最好的结果)
什么情况下扩容(缩容)呢?
比较常见的扩容情况是count > 0.75 * limit的时候进行扩容
常见缩容是 count < 0.25 * limit
先来解决质数的问题 判断是否是质数
1 2 3 4 5 6 7 8 9 10 11 12 HashTable .prototype isPrime = function (num ) { var temp = parseInt (Math .sqrt (num)); for (var i = 2 ; i <= temp; i++) { if (num % i == 0 ) { return false ; } } return true ; }
获取质数
1 2 3 4 5 6 7 HashTable .prototype getPrime = function (num ) { while (!this .isPrime (num)) { num++; } return num; }
哈希表扩容代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 HashTable .prototype resize = function (newLimit ) { var oldStorage = this .storage ; this .storage = []; this .count = 0 ; this .limit = newLimit; for (var i = 0 ; i < oldStorage.length ; i++) { var bucket = oldStorage[i]; if (bucket == null ) { continue ; } for (var j = 0 ; j < bucket.length ; j++) { var tuple = bucket[j]; this .put (tuple[0 ], tuple[1 ]); } } }
完善添加和修改函数的代码
在添加和删除后要进行判断是否需要扩容和缩容
添加操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 HashTable .prototype put = function (key, value ) { var index = this .hashFunc (key, this .limit ); var bucket = this .storage [index] if (bucket === undefined ) { bucket = []; this .storage [index] = bucket; } for (var i = 0 ; i < bucket.length ; i++) { var tuple = bucket[i]; if (key == tuple[0 ]) { tuple[1 ] = value; return } } bucket.push ([key, value]); this .count += 1 ; if (this .count > this .limit * 0.75 ) { var newSize = this .limit * 2 ; var newPrime = this .getPrime (newSize); this .resize (newPrime) } }
删除方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 HashTable .prototype remove = function (key ) { var index = this .hashFunc (key, this .limit ); var bucket = this .storage [index]; if (bucket == null ) return null ; for (var i = 0 ; i < bucket.length ; i++) { var tuple = bucket[i]; if (key == tuple[0 ]) { bucket.splice (i, 1 ); this .count -= 1 ; if (this .limit > 7 && this .count < this .limit * 0.25 ) { var newSize = Math .floor (this .limit / 2 ); var newPrime = this .getPrime (newSize); this .resize (newPrime); } return tuple[1 ]; } } return null ; }
哈希表解决leetcode常见题 有效的字母异或位词 地址:https://leetcode.cn/problems/valid-anagram/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 var isAnagram = function (s, t ) { let map = new Map (); for (let i = 0 ; i < s.length ; i++) { if (map.has (s[i])) { let count = map.get (s[i]); count++; map.set (s[i], count); } else { map.set (s[i], 1 ); } } for (let i = 0 ;i < t.length ; i++) { if (map.has (t[i])) { let count = map.get (t[i]); count--; if (count == 0 ) { map.delete (t[i]); } else { map.set (t[i], count); } } else { return false ; } } if (map.size > 0 ) return false ; return true ; };
两个数组的交集 地址:https://leetcode.cn/problems/intersection-of-two-arrays/
还是经典哈希表解决
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 var intersection = function (nums1, nums2 ) { let map = new Map (); for (let i = 0 ; i < nums1.length ; i++) { if (!map.has (nums1[i])) { map.set (nums1[i], false ); } } for (let i = 0 ; i < nums2.length ; i++) { if (map.has (nums2[i])) { map.set (nums2[i], true ); } } let res = []; for (let item of map) { if (item[1 ]) { res.push (item[0 ]); } } return res; };
快乐数 地址:https://leetcode.cn/problems/happy-number/
题目中说了会 无限循环 ,那么也就是说求和的过程中,sum会重复出现 ,重复出现了就不是快乐数,直接return false。用哈希表来判断重复。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 function splitSum (n ) { let str = n + '' ; let arr = str.split ('' ); let sum = 0 ; for (let num of arr) { sum += num * num; } return sum; } var isHappy = function (n ) { let set = new Set (); let sum = splitSum (n); while (true ) { if (sum == 1 ) { return true ; } else { if (set.has (sum)) { return false ; } else { set.add (sum); sum = splitSum (sum); } } } };
两数之和 地址:https://leetcode.cn/problems/two-sum/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 var twoSum = function (nums, target ) { let map = new Map (); for (let i = 0 ; i < nums.length ; i++) { if (map.has (target - nums[i])) { return [i, map.get (target - nums[i])] } else { map.set (nums[i], i) } } };
四数相加|| 地址:https://leetcode.cn/problems/4sum-ii/
妈的,这题是要求数量,不是要具体的索引,麻了,不看题解感觉永远解不出来。。。
看官方题解:
我们可以将四个数组分成两部分,A 和 B 为一组,C 和 D 为另外一组。
对于 A 和 B,我们使用二重循环对它们进行遍历,得到所有 A[i]+B[j]A[i]+B[j] 的值并存入哈希映射中。对于哈希映射中的每个键值对,每个键表示一种 A[i]+B[j]A[i]+B[j],对应的值为 A[i]+B[j]A[i]+B[j] 出现的次数。
对于 C 和 D,我们同样使用二重循环对它们进行遍历。当遍历到 C[k]+D[l]C[k]+D[l] 时,如果 -(C[k]+D[l])−(C[k]+D[l]) 出现在哈希映射中,那么将 -(C[k]+D[l])−(C[k]+D[l]) 对应的值累加进答案中。
最终即可得到满足 A[i]+B[j]+C[k]+D[l]=0A[i]+B[j]+C[k]+D[l]=0 的四元组数目。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 var fourSumCount = function (nums1, nums2, nums3, nums4 ) { let map = new Map (); for (let item of nums1) { for (let item2 of nums2) { if (map.has (item + item2)) { let count = map.get (item + item2); count++; map.set ((item + item2), count) } else { map.set ((item + item2), 1 ) } } } let sum = 0 ; for (let item of nums3) { for (let item2 of nums4) { if (map.has (-(item + item2))) { sum += map.get (-(item + item2)) } } } return sum; };
赎金信 地址:https://leetcode.cn/problems/ransom-note/
两个方法:
第一种:数组API操作(效率较为低,因为频繁地对数组进行删除)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 var canConstruct = function (ransomNote, magazine ) { for (let i = 0 ; i < ransomNote.length ; i++) { let index = magazine.indexOf (ransomNote[i]); if (index != -1 ) { let arr = magazine.split ('' ); arr.splice (index, 1 ); magazine = arr.join ('' ); } else { return false ; } } return true ; };
第二种:哈希表(效率高)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 var canConstruct = function (ransomNote, magazine ) { let map = new Map () for (let i = 0 ; i < magazine.length ; i++) { if (map.has (magazine[i])) { let result = map.get (magazine[i]); result++; map.set (magazine[i], result) } else { map.set (magazine[i], 1 ) } } for (let i = 0 ; i < ransomNote.length ; i++) { if (map.has (ransomNote[i])) { let result = map.get (ransomNote[i]); result--; if (result == 0 ) { map.delete (ransomNote[i]) } else { map.set (ransomNote[i], result) } } else { return false ; } } return true ; };